Mahout推荐算法

Mahout推荐算法
DreamCollector1. Mahout推荐算法
Mahout完整的封装了
协同过滤算法,根据相似度来推荐目标
2. 相关依赖
1 | <!--Mahout推荐算法--> |
3. Recommender的API接口
| Recommender接口方法 | 描述 |
|---|---|
| recommend(long userID, int howMany) | 获得推荐结果,给userID推荐howMany个Item |
| recommend(long userID, int howMany, IDRescorer rescorer) | 获得推荐结果,给userID推荐howMany个Item,可以根据rescorer对结构重新排序 |
| estimatePreference(long userID, long itemID) | 当打分为空,估计用户对物品的打分 |
| setPreference(long userID, long itemID, float value) | 赋值用户,物品,打分 |
| removePreference(long userID, long itemID) | 删除用户对物品的打分 |
| getDataModel() | 提取推荐数据 |
| Recommender接口的继承子类(推荐算法实现类) | 描述 |
|---|---|
| GenericUserBasedRecommender | 基于用户的推荐算法 |
| GenericItemBasedRecommender | 基于物品的推荐算法 |
| KnnItemBasedRecommender | 基于物品的KNN推荐算法(mahout_v0.8已弃用) |
| SlopeOneRecommender | Slope推荐算法(mahout_v0.8已弃用) |
| SVDRecommender | SVD推荐算法 |
| TreeClusteringRecommender:TreeCluster | TreeCluster推荐算法(mahout_v0.8已弃用) |
4. 常用的算法
4.1. 基于用户的协同过滤算法
算法原理:给用户推荐和他兴趣类似的其余用户喜欢的物品
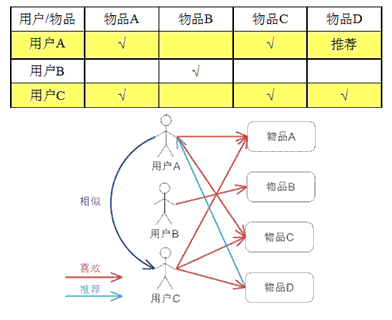
图述:对于用户 A,根据用户的历史偏好,这里只计算获得一个邻居 – 用户 C,而后将用户 C 喜欢的物品 D 推荐给用户 A
简述:基于用户对物品的偏好找到相邻邻居用户,而后将邻居用户喜欢的推荐给当前用户
实现:将一个用户对全部物品的偏好做为一个向量 来计算用户之间的类似度,找到 K 邻居后,根据邻居的类似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算获得一个排序的物品列表做为推荐
4.2. 基于物品的协同过滤算法
算法原理:给用户推荐和他以前喜欢的物品类似的物品
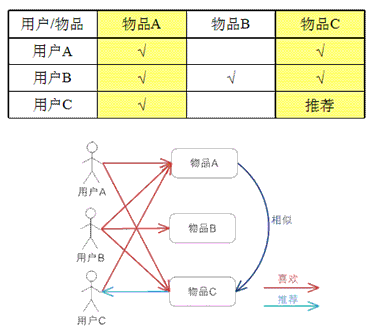
图述:对于物品 A,根据全部用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较类似,而用户 C 喜欢物品 A,那么能够推断出用户 C 可能也喜欢物品 C
简述:基于物品的协同过滤算法原理和基于用户相似,只是在计算邻居时采用物品自己,而不是从用户的角度,即基于用户对物品的偏好找到类似的物品,而后根据用户的历史偏好,推荐类似的物品给他
实现:将全部用户对某个物品的偏好做为一个向量来计算物品之间的类似度,获得物品的类似物品后,根据用户历史的偏好预测当前用户尚未表示偏好的 物品,计算获得一个排序的物品列表做为推荐
5. 例子:
以下为所需表结构:
| Table字段(user_book_score评分表) | 描述 |
|---|---|
| id | 主键ID |
| user_pk | 用户ID |
| book_pk | 书ID |
| score | 评分 |
| update_time | 时间 |
1 | DataModel dataModel = new MySQLJDBCDataModel(dataSource, "user_book_score", "user_pk" |


喜欢这篇文章的人也看了
评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果

公告
欢迎来看我的博客鸭~ 

退出:esc
方向控制: ←↑→
射击:Space
轰炸:B
