Deepseek本地搭建教程

Deepseek本地搭建教程
DreamCollector由于近期Deepseek的大模型还是比较火,但是官方的请求比较拥挤,所以就出个教程来让大家本地运行模型把~
一、简介
DeepSeek是一家成立于2023年7月的人工智能基础技术公司,总部位于杭州,由知名量化资管机构幻方量化创立。公司专注于开发先进的大语言模型(LLM)及相关技术,致力于通过高效算法和优化模型架构,在AI领域迅速崛起。主要产品包括:
DeepSeek-R1:这是一款开源、免费且强大的推理模型,擅长处理复杂任务,如数学推理、代码生成、自然语言理解等。其性能在多个评测中优于其他模型,如OpenAI的GPT-4-o mini,并且成本远低于国际顶尖模型。
DeepSeek-V3:这是公司推出的最新版本模型,具备卓越的文本处理能力,适用于日常对话、专业问答和写作任务。其训练成本低至557.6万美元,性价比极高。
DeepSeek Chat:一款智能对话助手,提供创意写作、摘要翻译等功能。
DeepSeek Coder:专门面向程序员的智能编程助手,具备代码生成和优化功能。
二、模型配置推荐
| 模型参数 | Win配置要求 | Mac配置要求 | 适用场景 |
|---|---|---|---|
| 1.5B | RAM:4GB GPU:集成显卡(如GTX 1050)或现代 存储:5GB |
内存:6GB(统一内存) 芯片:M1/M2/M3 存储:5GB |
简单文本生成/基础代码补全 |
| 7B | RAM:8GB~10GB GPU:GTX 1660(4-bit量化) 存储:8GB |
内存:16GB 芯片:M2 Pro/M3 存储:8GB |
中等复杂问答/代码调试 |
| 8B | RAM:12GB GPU:RTX 3060⬆(8GB VRAM) 存储:10GB |
内存:24GB 芯片:M2 Max 存储:10GB |
多轮对话/文档分析 |
| 14B | RAM:24GB GPU:RTX 3090(24GB VRAM) 存储:20GB |
内存:32GB 芯片:M3 Max 存储:20GB |
复杂推理/技术文档生成 |
| 32B | RAM:48GB GPU:RTX 4090(4-bit量化) 存储:40GB |
内存:64GB 芯片:M3 UItra 存储:40GB |
科研计算/大规模数据处理 |
| 70B | RAM:64GB GPU:双RTX 4090(NVLINK) 存储:80GB |
内存:128GB(需外接显卡坞) 存储:80GB |
企业AI服务/多模态处理 |
| 671B | RAM:256GB⬆ GPU:8xH100(通过NVLINK 连接) 存储:1TB⬆ |
暂不支持 | 超大规模云端推理 |
三、安装Ollma
Ollma是一个开源的大模型服务工具,同类的产品也有LM Studio和vLLM,以下介绍均为Win的安装,其他平台大同小异
- Ollama:
- 开源与定制化:Ollama 是一个开源工具,支持自定义语言模型的建立和运行,适合开发者和技术熟练者。
- 易用性与灵活性:Ollama 界面简洁,支持多种预训练模型,提供灵活的微调选择和便捷的协作功能,但定制选项有限且成本较高。
- 技术优势:支持 GPU 和 Docker 部署,兼容 OpenAI API,适合需要快速部署和高效处理请求的用户。
- 适用人群:适合命令行界面熟悉者和技术开发者。
vLLM:
- 性能与扩展性:vLLM 专注于高效推理,优化了大规模语言模型的性能,特别是在分布式系统中。支持在多 GPU 和多节点环境下进行推理。
- 资源利用:具有高效的资源利用率,支持模型量化和优化,使其能够在硬件资源较为紧张的情况下高效运行。
- 兼容性:兼容主流的开源 LLM,能够与其他框架无缝集成,适用于需要大规模推理的环境。
- 适用人群:适合需要进行高并发推理和大规模模型部署的开发者和企业。
- LM Studio:
- 功能丰富:LM Studio 提供丰富的功能,包括分布式训练、超参数调整和模型优化,适合高级用户。
- 用户友好:内置聊天界面,支持多种本地语言模型操作和模型目录,界面友好,适合非技术用户。
- 商业支持:LM Studio 具有强大的商业支持,适合追求功能丰富的用户。
- 适用人群:适合初学者和普通用户进行创意写作、文本探索和模型生成。
综合总结:
- 易用性: Ollama 更适合技术熟练者,提供灵活的部署选项。而LM Studio更适合初学者和非技术用户,界面友好,使用简单。
功能与灵活性: LM Studio功能更全面,支持分布式训练和模型优化。Ollama 提供灵活的微调功能,但定制选项有限。vLLM 注重推理性能,支持高并发的环境。
适用场景: Ollama适合需要快速部署和高效处理请求的开发者。LM Studio适合需要高级功能和商业支持的用户,尤其是在创意写作和文本生成领域。vLLM 适合需要大规模推理和资源优化的高性能应用场景。
1. 官网下载
访问 Ollama 官方网站, 下载Windows 的安装文件
1 | 1.或者通过更改默认安装路径进行安装(可选) |
2. 修改模型存储位置(可选)
ollama默认存放model文件的位置:
C:\Users{用户名}.ollama,只需在系统的环境变量中添加以下配置,其中E:\ollama为存放的路径
1 | 变量名:OLLAMA_MODELS |
3. 启用GPU加速(可选)

1 | 1.查看本机显卡参数 |
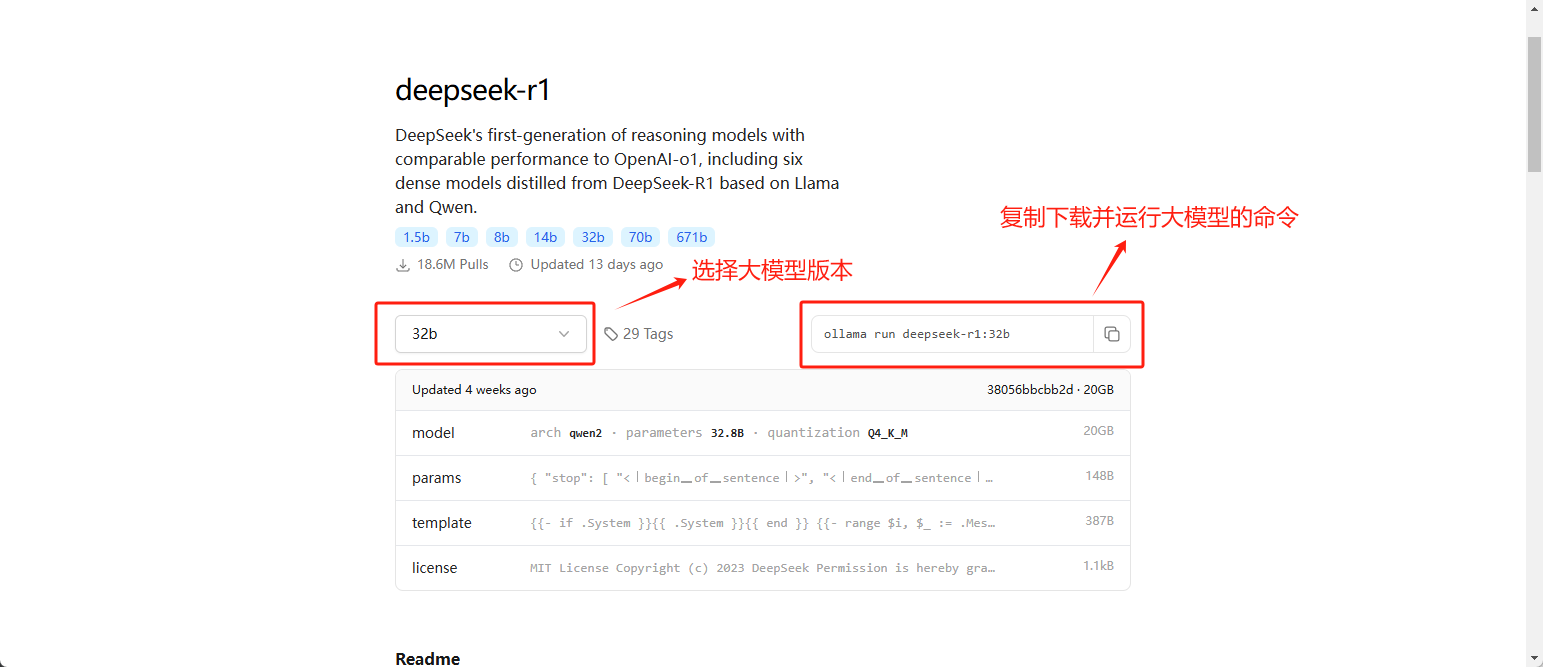
4. 下载大模型
通过访问 Ollama 开放模型官网,搜索下载对应的大模型,其中命令中的
deepseek-r1:32b为模型的名称
1 | 1.下载模型 |
四、安装Docker
1. 官网下载
访问 Docker 官方网站, 下载Windows 的安装文件,安装都选默认配置即可
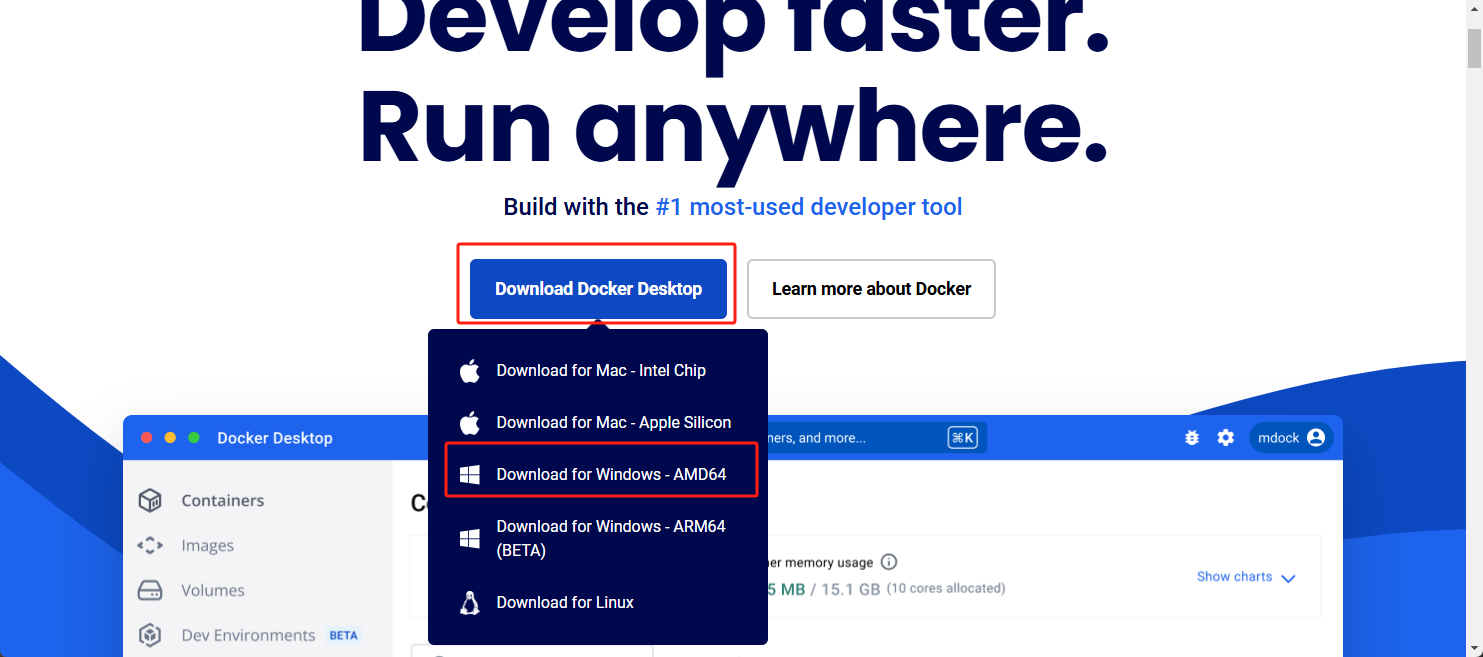
- Download for Windows - AMD64:适用于所有使用 x86-64 架构的处理器,包括 AMD 锐龙(Ryzen)、AMD Ryzen Threadripper、AMD EPYC 以及 Intel Core 系列等。
- Download for Windows - ARM64:适用于基于 ARM 架构的处理器,例如高通 Snapdragon、Apple M1/M2 等
2. 安装WSL
WSL 2(Windows Subsystem for Linux 2) 和 Hyper-V 是微软提供的两种不同的虚拟化技术,各有优缺点,适用于不同的使用场景。安装docker运行时需要WSL,以下是它们的区别、优缺点以及适用场景的详细比较
| 特性 | WSL 2 | Hyper-V |
|---|---|---|
| 定义 | 提供 Linux 子系统,允许直接运行完整 Linux 内核 | Windows 的完整虚拟化技术,用于运行虚拟机和服务 |
| 虚拟化方式 | 较轻量的虚拟化,基于虚拟机的 Linux 内核(使用 VM 技术) | 完整虚拟机,每个虚拟机拥有独立的资源和内核 |
| 内核 | 直接使用微软提供的 Linux 内核版本 | 完全分离的操作系统(可以运行多种操作系统) |
| 资源使用 | 更高效,内存和 CPU 分配动态调整 | 固定资源分配(根据虚拟机设置) |
| 用户体验 | 更接近本地 Linux 环境,深度集成 Windows | 完全独立,与 Windows 隔离 |
1 | 更新wsl没有的话会也会自动安装 |
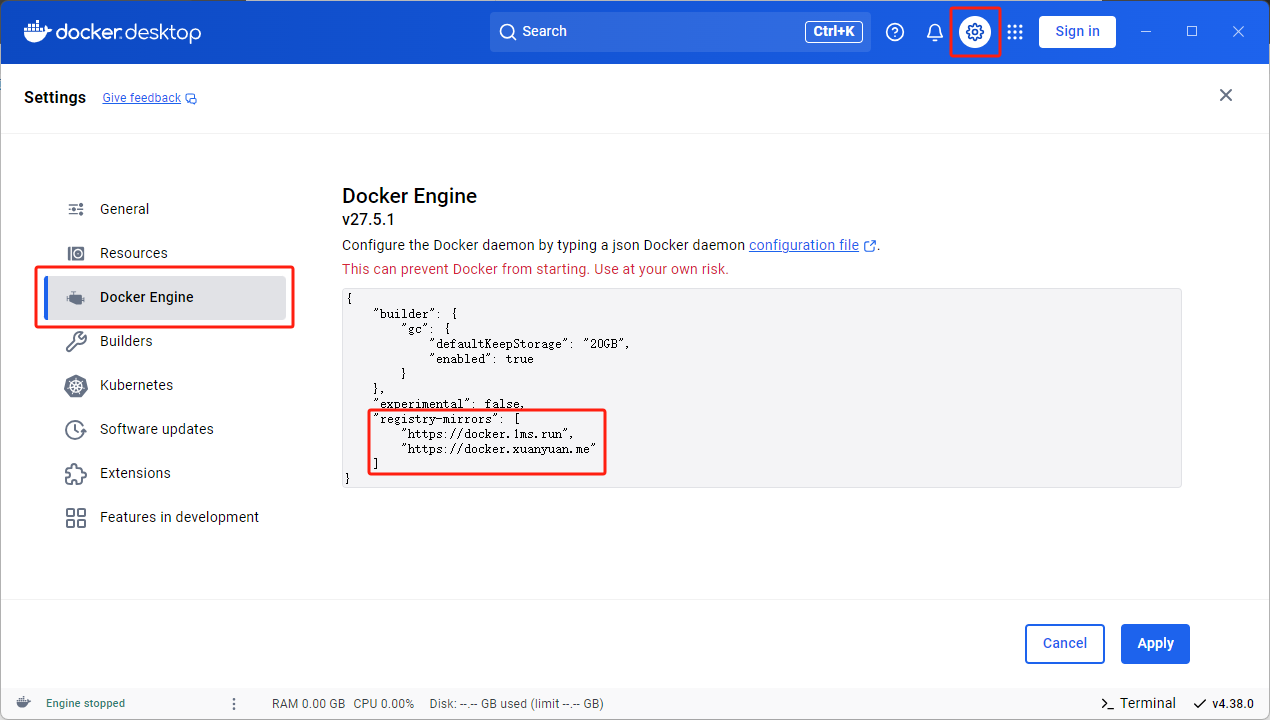
2. 更换镜像源
1 | // 新增Docker镜像源 |
3. 检查docker服务
WIN+R中运行
services.msc查看Docker Desktop Service服务是否已经启用,或者通过终端管理员shell终端执行以下命令
1 | 1.启动docker服务 |
4. 重启docker desktop
五、安装AnythingLLM
AnythingLLM用于与文档进行智能聊天或构建知识库。支持多种文档类型(如PDF、TXT、DOCX等),并能够与大语言模型(LLM)集成,以便在聊天中引用这些文档内容,通常跟ollama搭配作为本地的知识库检索。
1. docker下载镜像
也可访问 AnythingLLm 官方网站下载桌面端(不太推荐),桌面端相较于docker安装功能没那么多,具体差异可参考Desktop和Docker对比,Linux/Mac版本也可参考官方 docker命令
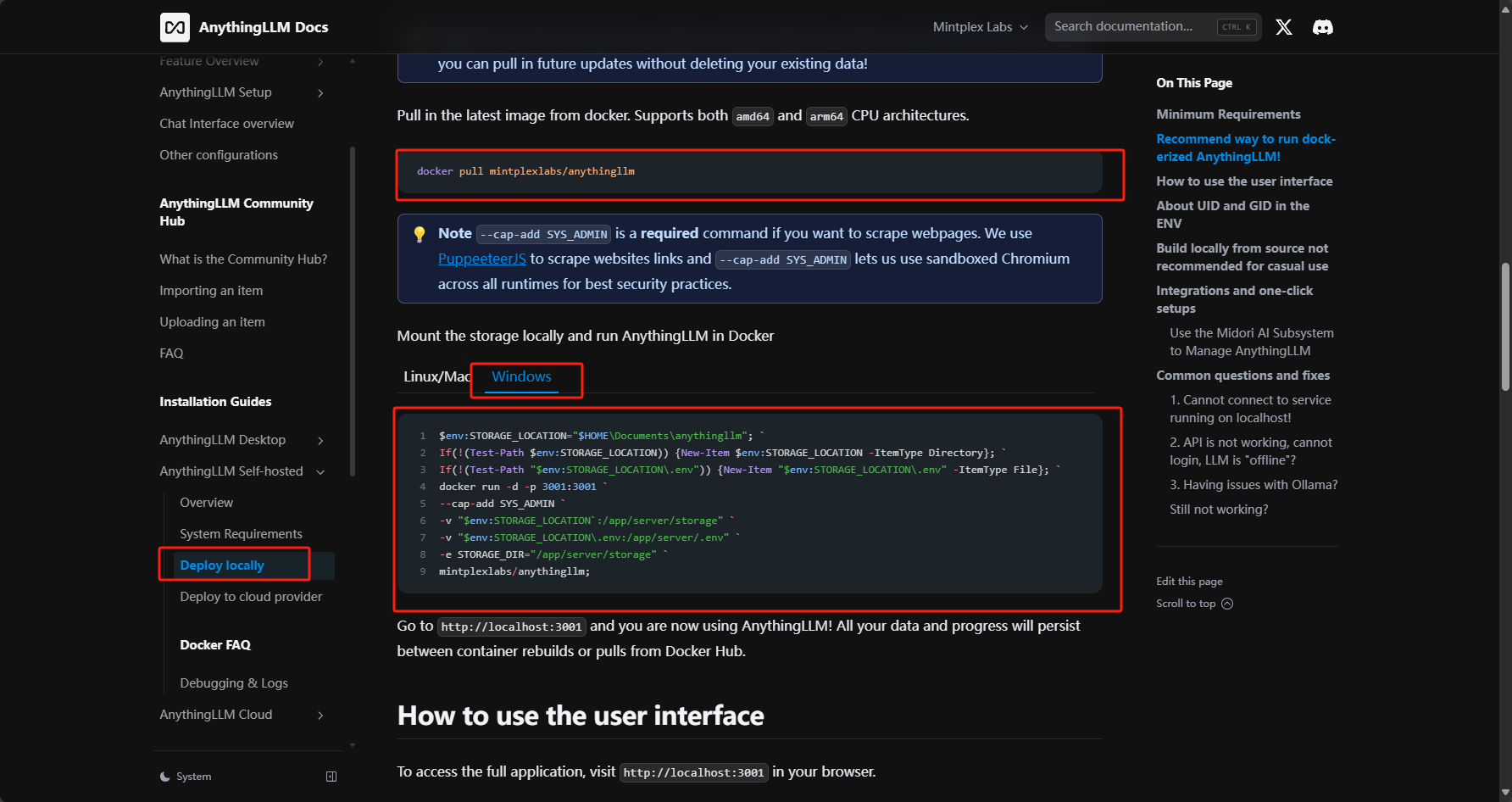
1 | 1.拉取anythingllm镜像 |
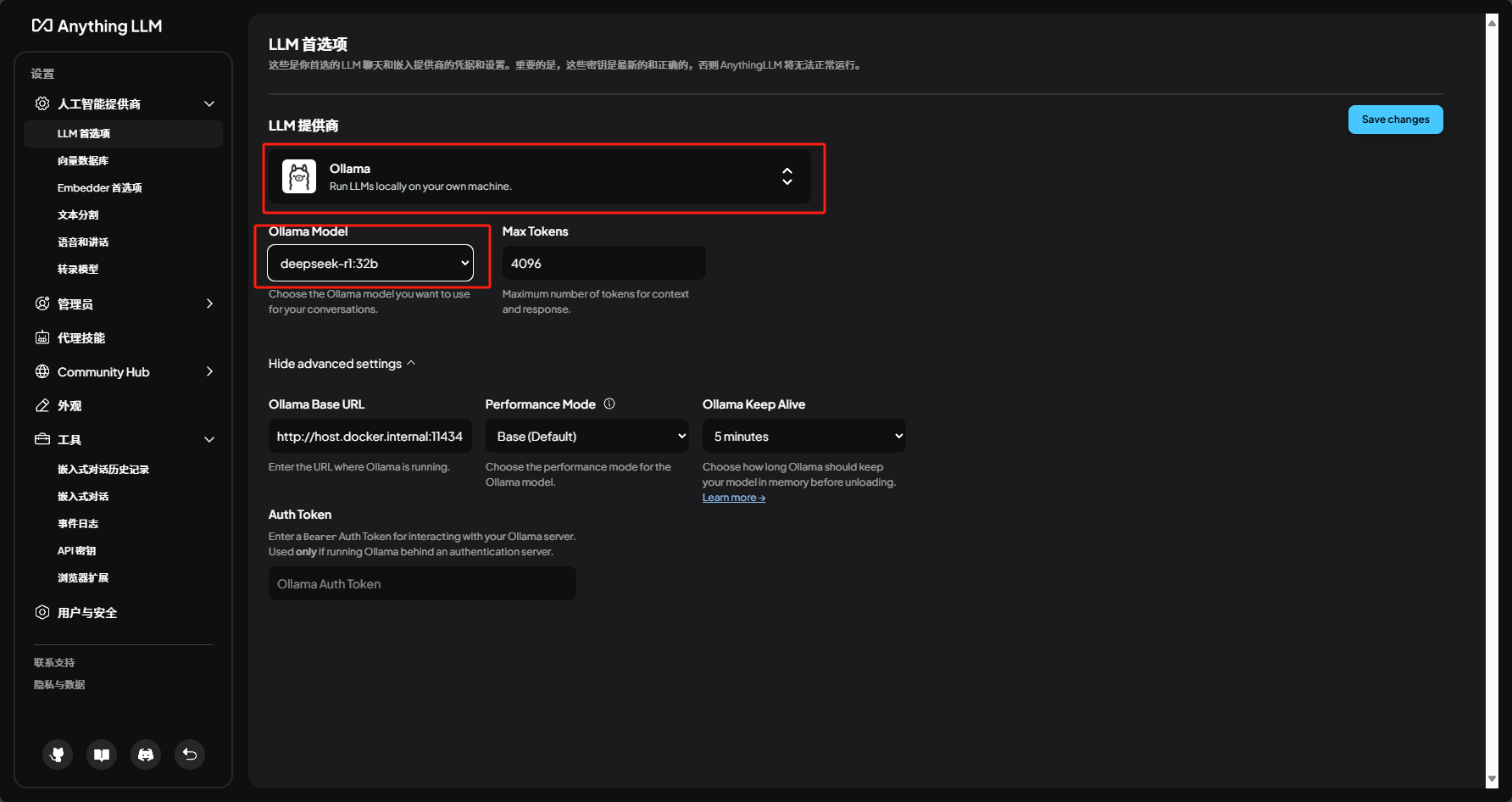
2. 运行并配置模型
网页中打开本地地址,进行LLM提供商的选择和大模型的选择,也可后续从设置中配置




退出:esc
方向控制: ←↑→
射击:Space
轰炸:B

